
สิ่งที่ได้รับจากการเรียนวิชาเตรียมฝึกประสบการณ์วิชาชีพ 3
ความมีระเบียบวินัย : ความมีระเบียบและวินัยในตัวเองนั้นเป็นสิ่งที่สำคัญยิ่ง คนเราต้องมีระเบียบอยู่ในกฎเกณฑ์ ทำอะไรก็ต้องลำดับก่อนหลังถึงจะอยู่ร่วมกันในสังคมได้อย่างสงบสุข การที่นักศึกษาควบคุมตนเอง ประพฤติปฏิบัติตนอย่างมีระเบียบแบบแผน มีเหตุผลและเป้าหมายในการเพิ่มพูนความรู้ สามารถพัฒนาตนเอง ไม่เฉพาะแต่วิชาเตรียมฝึกประสบการณ์วิชาชีพอย่างเดียวเท่านั้นแต่เราสามารถนำไปประยุกต์ใช้ได้กับทุกวิชาอีกด้วย
ความรับผิดชอบ :ในการเรียนวิชาเตรียมฝึกประการณ์วิชาชีพทำให้เรามีความรับผิดชอบ มีความตรงต่อเวลา ซึ่งมีผลดีกับตัวเราเอง เพราะตัวเราเองก็ต้องออกไปฝึกงานภายนอกถ้าเรามีความรับผิดชอบ มีความตรงต่อเวลา ก็จะทำให้เราสามารถทำงานร่วมกับผู้อื่นได้ และเป็นที่น่านับถือของคนในสังคมนั้นๆ
การตรงต่อเวลา :ในการดำรงชีวิตในปัจจุบันเราจะต้องเป็นคนที่ตรงต่อเวลา มีความรับผิดชอบในหน้าที่ที่เราควรทำ เพื่อที่จะได้ไม่ทำให้ผู้อื่นต้องมารอคอยหรือมาเดือดร้อนเพราะเรา
ความสามัคคี : ในการทำงานเราจะต้องให้ความร่วมกัมมือซึ่งกันและกัน เพื่องานชิ้นนั้นๆจะได้เสร็จสิ้นอย่างเรียบร้อยและสมบูรณ์ ถ้าหากเราทุกคนไม่มีความสามัคคีซึ่งกันและกันสังคมก็จะเกิดความวุ่นวาย
15.9.52
DTS 09-09-2552
Graph (ต่อ) และ Sorting
กราฟมีน้ำหนัก หมายถึง กราฟที่ทุกเอดจ์ มีค่าน้ำหนักกำกับ ซึ่งค่าน้ำหนักอาจสื่อถึงระยะทาง เวลา ค่าใช้จ่าย เป็นต้น นิยมนำไปใช้แก้ปัญหาหลัก ๆ 2 ปัญหา คือ
การสร้างต้นไม้ทอดข้ามน้อยที่สุด(Minimum Spanning Trees :MST)
1. เรียงลำดับเอดจ์ ตามน้ำหนัก
2. สร้างป่าที่ประกอบด้วยต้นไม้ว่างที่มีแต่โหนด และไม่มีเส้นเชื่อม
3. เลือกเอดจ์ที่มีน้ำหนักน้อยที่สุดและยังไม่เคยถูกเลือกเลย ถ้ามีน้ำหนักซ้ำกันหลายค่าให้สุ่มมา 1เส้น
4. พิจารณาเอดจ์ที่จะเลือก ถ้านำมาประกอบในต้นไม้ทอดข้ามน้อยที่สุดแล้วเกิด วงรอบ ให้ตัดทิ้งนอกนั้นให้นำมาประกอบเป็นเอดจ์ในต้นไม้ทอดข้ามน้อยที่สุด
5. ตรวจสอบเอดจ์ที่ต้องอ่านในกราฟ ถ้ายังอ่านไม่หมดให้ไปทำข้อ 3
การหาเส้นทางที่สั้นที่สุด (Shortest path) Dijkstra’s Algorithm
หาเส้นทางที่สั้นที่สุดจากโหนดต้นทางไปโหนดใด ๆ ในกราฟ มีน้ำหนัก และน้ำหนักไม่เป็นลบ
ข้อกำหนด
ให้ เซต S เก็บโหนดที่ผ่านได้และมีระยะทางห่างจากจุดเริ่มต้นสั้นที่สุดให้ W แทนโหนด นอกเซต Sให้ D แทนระยะทาง (distance) ที่สั้นที่สุดจากโหนดต้นทางไปโหนดใด ๆ ในกราฟ โดยวิถีนี้ประกอบด้วย โหนดในเชตให้ S ถ้าไม่มีวิถี ให้แทนด้วยค่าอินฟินีตี้ (Infinity) : ∞
Sorting
การเรียงลำดับ (sorting) เป็นการจัดให้เป็นระเบียบมีแบบแผน ช่วยให้การค้นหาสิ่งของหรือข้อมูล ซึ่งจะสามารถกระทำได้รวดเร็วและมีประสิทธิภาพ เช่น การค้นหาคำตามตัวอักษรไว้อย่างมีระบบและเป็นระเบียบ หรือ การค้นหาหมายเลขโทรศัพท์ในสมุดโทรศัพท์ ซึ่งมีการเรียงลำดับ ตามชื่อและชื่อสกุลของเจ้าของโทรศัพท์ไว้ ทำให้สามารถค้นหา หมายเลขโทรศัพท์ของคนที่ต้องการได้อย่างรวดเร็ว
วิธีการเรียงลำดับสามารถแบ่งออกเป็น 2 ประเภท คือ
การเรียงลำดับแบบภายใน (internal sorting) เป็น การเรียงลำดับที่ข้อมูลทั้งหมดต้องอยู่ในหน่วยความจำหลัก เวลาที่ใช้ในการเรียงลำดับจะคำนึงถึงเวลาที่ใช้ในการเปรียบเทียบและเลื่อน ข้อมูลภายในความจำหลัก
การเรียงลำดับแบบภายนอก(external sorting) เป็นการเรียงลำดับข้อมูลที่เก็บอยู่ในหน่วยความจำสำรอง ซึ่งเป็นการเรียงลำดับข้อมูลในแฟ้มข้อมูล (file) เวลาที่ใช้ในการเรียงลำดับต้องคำนึงถึงเวลาที่เสียไประหว่างการถ่ายเทข้อมูล จากหน่วยความจำหลักและหน่วยความจำสำรองนอกเหนือจากเวลาที่ใช้ในการเรียง ลำดับข้อมูลแบบภายในการเรียงลำดับแบบเลือก (selection sort)ทำการเลือกข้อมูลมาเก็บในตำแหน่งที่ ข้อมูลนั้นควรจะอยู่ทีละตัว โดยทำการค้นหาข้อมูลนั้นในแต่ละรอบแบบเรียงลำดับ
การเรียงลำดับแบบภายใน (internal sorting) เป็น การเรียงลำดับที่ข้อมูลทั้งหมดต้องอยู่ในหน่วยความจำหลัก เวลาที่ใช้ในการเรียงลำดับจะคำนึงถึงเวลาที่ใช้ในการเปรียบเทียบและเลื่อน ข้อมูลภายในความจำหลัก
การเรียงลำดับแบบภายนอก(external sorting) เป็นการเรียงลำดับข้อมูลที่เก็บอยู่ในหน่วยความจำสำรอง ซึ่งเป็นการเรียงลำดับข้อมูลในแฟ้มข้อมูล (file) เวลาที่ใช้ในการเรียงลำดับต้องคำนึงถึงเวลาที่เสียไประหว่างการถ่ายเทข้อมูล จากหน่วยความจำหลักและหน่วยความจำสำรองนอกเหนือจากเวลาที่ใช้ในการเรียง ลำดับข้อมูลแบบภายในการเรียงลำดับแบบเลือก (selection sort)ทำการเลือกข้อมูลมาเก็บในตำแหน่งที่ ข้อมูลนั้นควรจะอยู่ทีละตัว โดยทำการค้นหาข้อมูลนั้นในแต่ละรอบแบบเรียงลำดับ
การเรียงลำดับแบบเลือก
เป็น วิธีที่ง่าย แต่เสียเวลาในการจัดเรียงนาน โดยจะทำการเลือกข้อมูลมาเก็บไว้ตามตำแหน่งที่กำหนด คือ กำหนดให้เรียงข้อมูลจากค่าน้อยไปหาค่ามาก ก็จะทำการเลือกข้อมูลตัวที่มีค่าน้อยที่สุดมาอยู่ที่ตำแหน่งแรกสุด และค่าที่อยู่ตำแหน่งแรกก็จะมาอยู่แทนที่ค่าน้อยสุด แล้วทำการเลือกไปเรื่อยๆ จนครบทุกค่า ค่าที่ได้ก็จะเรียงจากน้อยไปหามาก
การเรียงลำดับแบบฟอง (Bubble Sort)
เป็น วิธีการเรียงลำดับที่มีการเปรียบเทียบข้อมูลในตำแหน่งที่อยู่ติดกัน1. ถ้าข้อมูลทั้งสองไม่อยู่ในลำดับที่ถูกต้องให้สลับตำแหน่งที่อยู่กัน2. ถ้าเป็นการเรียงลำดับจากน้อยไปมากให้นำข้อมูลตัวที่มีค่าน้อยกว่าอยู่ใน ตำแหน่งก่อนข้อมูลที่มีค่ามาก ถ้าเป็นการเรียงลำดับจากมากไปน้อยให้นำข้อมูล ตัวที่มีค่ามากกว่าอยู่ในตำแหน่งก่อนข้อมูลที่มีค่าน้อย
การเรียงลำดับแบบแทรก (insertion sort)
เป็น วิธีการเรียงลำดับที่ทำการเพิ่มสมาชิกใหม่เข้าไปในเซต ที่มีสมาชิกทุกตัวเรียงลำดับอยู่แล้ว และทำให้เซตใหม่ที่ได้นี้มีสมาชิกทุกตัวเรียงลำดับด้วย วิธีการเรียงลำดับจะ
1. เริ่มต้นเปรียบเทียบจากข้อมูลในตำแหน่งที่ 1 กับ 2หรือข้อมูลในตำแหน่งสุดท้ายและรองสุดท้ายก็ได้ถ้าเป็นการเรียงลำดับจากน้อย ไปมาก
2. จะต้องจัดให้ข้อมูลที่มีค่าน้อยอยู่ในตำแหน่งก่อนข้อมูลที่มีค่ามาก และถ้าเรียงจากมากไปน้อยก็จะจัดให้ข้อมูลที่มีค่ามากอยู่ในตำแหน่งก่อน
1. เริ่มต้นเปรียบเทียบจากข้อมูลในตำแหน่งที่ 1 กับ 2หรือข้อมูลในตำแหน่งสุดท้ายและรองสุดท้ายก็ได้ถ้าเป็นการเรียงลำดับจากน้อย ไปมาก
2. จะต้องจัดให้ข้อมูลที่มีค่าน้อยอยู่ในตำแหน่งก่อนข้อมูลที่มีค่ามาก และถ้าเรียงจากมากไปน้อยก็จะจัดให้ข้อมูลที่มีค่ามากอยู่ในตำแหน่งก่อน
การเรียงลำดับแบบฐาน
เป็น วิธีที่พิจารณาเลขที่ละหลัก โดยจะพิจารณาเลขหลักหน่วยก่อน แล้วทำการจัดเรียงข้อมูลทีละตัวตามกลุ่มหมายเลข จากนั้นนำข้อมูลที่จัดเรียงในหลักหน่วยมาจัดเรียงในหลักสิยต่อไปเรื่อยๆจน ครบทุกหลัก ก็จะได้ข้อมูลที่ต้องการ การเรียงลำดับแบบฐานไม่ซับซ้อน แต่ใช้เนื้อที่ในหน่วยความจำมาก
เป็น วิธีที่พิจารณาเลขที่ละหลัก โดยจะพิจารณาเลขหลักหน่วยก่อน แล้วทำการจัดเรียงข้อมูลทีละตัวตามกลุ่มหมายเลข จากนั้นนำข้อมูลที่จัดเรียงในหลักหน่วยมาจัดเรียงในหลักสิยต่อไปเรื่อยๆจน ครบทุกหลัก ก็จะได้ข้อมูลที่ต้องการ การเรียงลำดับแบบฐานไม่ซับซ้อน แต่ใช้เนื้อที่ในหน่วยความจำมาก
4.9.52
DTS 04/09/2552
สรุปเนื้อหาบทเรียน เรื่อง Graph
กราฟ (Graph) เป็นโครงสร้างข้อมูลแบบไม่ใช่เชิงเส้น อีกชนิดหนึ่ง กราฟเป็นโครงสร้างข้อมูลที่มีการนำไปใช้ในงานที่เกี่ยวข้องกับการแก้ปัญหาที่ค่อนข้างซับซ้อน
นิยามของกราฟ
1. โหนด(Nodes) หรือ เวอร์เทกซ์ (Vertexes)
2. เส้นเชื่อมระหว่างโหนด เรียก เอ็จ (Edges)
กราฟที่มีเอ็จเชื่อมระหว่างโหนดสองโหนด ถ้าเอ็จไม่มีลำดับ ความสัมพันธ์จะเรียกกราฟนั้นว่า กราฟแบบไม่มีทิศทาง (Undirected Graph) และถ้ากราฟนั้นมีเอ็จที่มีลำดับ ความสัมพันธ์หรือมีทิศทางกำกับด้วย เรียกกราฟนั้นว่า กราฟแบบมีทิศทาง (Directed Graph) บางครั้งเรียกว่า ไดกราฟ (Digraph) ถ้าต้องการอ้างถึงเอ็จแต่ละเส้นสามารถเขียนชื่อเอ็จกำกับไว้ก็ได้
การแทนกราฟในหน่วยความจำ
ในการปฎิบัติการกับโครงสร้างกราฟ สิ่งที่ต้อการจัดเก็บ จากกราฟโดยทั่วไป คือ เอ็จ ซึ่งเป็นเส้นเชื่อมระหว่างโหนดสองโหนด มีวิธีการจัดเก็บหลายวิธี วิธีที่ง่ายและตรงไปตรมาที่สุด คือ การเก็บเอ็จในแถวลำดับ 2 มิติ จะค่อนข้างเปลืองเนื้อที่ เนื่องจากมีบางเอ็จที่เก็บซ้ำ อาจหลีกเลี่ยงปัญหานี้ได้โดยใช้แถวลำดับ 2 มิติ เก็บโหนดและพอยเตอร์ ชี้ไปยัตำแหน่งของโหนดต่างๆที่สัมพันธ์ด้วย และใช้แถวลำดับ 1 มิติ เก็บโหนดต่างๆที่มีความสัมพันธ์กับโหนดในแถวลำดับ 2 มิติ
กราฟที่มีการเปลี่ยนแปลงตลอดเวลาอาจจะใช้วิธี แอดจาเซนซีลิสต์ (Adjacency List) ซึ่งเป็นวิธีที่คล้ายวิธีจัดเก็บกราฟด้วยการเก็บโหนดและพอยเตอร์ แต่ต่างกันตรงที่ จะใช้ลิงค์ลิสต์แทน เพื่อความสะดวกในการเปลี่ยนแปลงแก้ไข
การท่องไปในกราฟ (Graph Traversal)
คือ กระบวนการเข้าไปเยือนโหนดในกราฟ โดยมีหลักในการทำงานคือ แต่ละโหนดจะถูกเยือนเพียงครั้งเดียว สำหรับการท่องไปในทรี เพื่อเยือนแต่ะโหนดนั้น จะมีเส้นทางเดียวแต่ในกราฟระหว่างโหนดอาจจะมีหลายเส้นทาง เพื่อป้องกันการท่องไปในเส้นทางที่ซ้ำเดิมจึจำเป็นต้องทำเครื่องหมายบริเวณที่ได้เยือนเสร็จเรียบร้อยแล้ว
1. การท่องแบบกว้าง (Breadth First Traversal) วิธีนี้ทำได้โดยเลือกโหนดที่เป็นจุดเริ่มต้น ต่อมาให้เยือนโหนดอื่นที่ใกล้กันกับโหนดเริ่มต้นทีละระดับจนกระทั่งเยือนหมดทุกโหนดในกราฟ
2. การท่องแบบลึก (Depth First Traversal) การทำงานคล้ายกับการท่องทีละระดับของทรี โดยกำหนดเริ่มต้นที่โหนดแรก และเยือนโหนดถัดไป ตามแนววิถีนั้น จนกระทั่งนำไปสู่ปลายวิถีนั้น จากนั้น(Backtrack)ย้อนกลับ ตามแนววิถีเดิมนั้น จนกระทั่งสามารถดำเนินการ ต่อเนื่องเข้าสู่แนววิถีอื่นๆ เพื่อเยือนโหนดอื่นๆต่อไปจนครบทุกโหนด
กราฟ (Graph) เป็นโครงสร้างข้อมูลแบบไม่ใช่เชิงเส้น อีกชนิดหนึ่ง กราฟเป็นโครงสร้างข้อมูลที่มีการนำไปใช้ในงานที่เกี่ยวข้องกับการแก้ปัญหาที่ค่อนข้างซับซ้อน
นิยามของกราฟ
1. โหนด(Nodes) หรือ เวอร์เทกซ์ (Vertexes)
2. เส้นเชื่อมระหว่างโหนด เรียก เอ็จ (Edges)
กราฟที่มีเอ็จเชื่อมระหว่างโหนดสองโหนด ถ้าเอ็จไม่มีลำดับ ความสัมพันธ์จะเรียกกราฟนั้นว่า กราฟแบบไม่มีทิศทาง (Undirected Graph) และถ้ากราฟนั้นมีเอ็จที่มีลำดับ ความสัมพันธ์หรือมีทิศทางกำกับด้วย เรียกกราฟนั้นว่า กราฟแบบมีทิศทาง (Directed Graph) บางครั้งเรียกว่า ไดกราฟ (Digraph) ถ้าต้องการอ้างถึงเอ็จแต่ละเส้นสามารถเขียนชื่อเอ็จกำกับไว้ก็ได้
การแทนกราฟในหน่วยความจำ
ในการปฎิบัติการกับโครงสร้างกราฟ สิ่งที่ต้อการจัดเก็บ จากกราฟโดยทั่วไป คือ เอ็จ ซึ่งเป็นเส้นเชื่อมระหว่างโหนดสองโหนด มีวิธีการจัดเก็บหลายวิธี วิธีที่ง่ายและตรงไปตรมาที่สุด คือ การเก็บเอ็จในแถวลำดับ 2 มิติ จะค่อนข้างเปลืองเนื้อที่ เนื่องจากมีบางเอ็จที่เก็บซ้ำ อาจหลีกเลี่ยงปัญหานี้ได้โดยใช้แถวลำดับ 2 มิติ เก็บโหนดและพอยเตอร์ ชี้ไปยัตำแหน่งของโหนดต่างๆที่สัมพันธ์ด้วย และใช้แถวลำดับ 1 มิติ เก็บโหนดต่างๆที่มีความสัมพันธ์กับโหนดในแถวลำดับ 2 มิติ
กราฟที่มีการเปลี่ยนแปลงตลอดเวลาอาจจะใช้วิธี แอดจาเซนซีลิสต์ (Adjacency List) ซึ่งเป็นวิธีที่คล้ายวิธีจัดเก็บกราฟด้วยการเก็บโหนดและพอยเตอร์ แต่ต่างกันตรงที่ จะใช้ลิงค์ลิสต์แทน เพื่อความสะดวกในการเปลี่ยนแปลงแก้ไข
การท่องไปในกราฟ (Graph Traversal)
คือ กระบวนการเข้าไปเยือนโหนดในกราฟ โดยมีหลักในการทำงานคือ แต่ละโหนดจะถูกเยือนเพียงครั้งเดียว สำหรับการท่องไปในทรี เพื่อเยือนแต่ะโหนดนั้น จะมีเส้นทางเดียวแต่ในกราฟระหว่างโหนดอาจจะมีหลายเส้นทาง เพื่อป้องกันการท่องไปในเส้นทางที่ซ้ำเดิมจึจำเป็นต้องทำเครื่องหมายบริเวณที่ได้เยือนเสร็จเรียบร้อยแล้ว
1. การท่องแบบกว้าง (Breadth First Traversal) วิธีนี้ทำได้โดยเลือกโหนดที่เป็นจุดเริ่มต้น ต่อมาให้เยือนโหนดอื่นที่ใกล้กันกับโหนดเริ่มต้นทีละระดับจนกระทั่งเยือนหมดทุกโหนดในกราฟ
2. การท่องแบบลึก (Depth First Traversal) การทำงานคล้ายกับการท่องทีละระดับของทรี โดยกำหนดเริ่มต้นที่โหนดแรก และเยือนโหนดถัดไป ตามแนววิถีนั้น จนกระทั่งนำไปสู่ปลายวิถีนั้น จากนั้น(Backtrack)ย้อนกลับ ตามแนววิถีเดิมนั้น จนกระทั่งสามารถดำเนินการ ต่อเนื่องเข้าสู่แนววิถีอื่นๆ เพื่อเยือนโหนดอื่นๆต่อไปจนครบทุกโหนด
1.9.52
DTS 01-09-52
สรุปเนื้อหาบทเรียน เรื่อง Tree
ทรี (Tree) เป็นโครงสร้างข้อมูลที่มีความสัมพันธ์กัน ระหว่าง โหนดจะมีความสัมพันธ์ลดหลั่นกันเป็นลำดับชั้น ส่วนมากจะใช้สำหรับ แสดงความสัมพันธ์ระหว่างข้อมูล ในทรีหนึ่งทรีจะประกอบไปด้วยรูทโหนด (root node) เพียงหนึ่งโหนด แล้วรูทโหนดสามารถแตกโหนดออกเป็นโหนดย่อยๆ ได้อีกหลายโหนดเรียกว่าโหนดลูก (Child node) เมื่อมีโหนดลูกแล้ว โหนดลูกก็ยังสามารถแสดงเป็นโหนดพ่อแม่ (Parent Node) โดยการแตกโหนดออกเป็นโหนดย่อยๆได้อีก
นิยามของโครงสร้างต้นไม้
1. นิยามของทรีด้วยนิยามของกราฟ
2. นิยามทรีด้วยรูปแบบรีเคอร์ซีฟ
นิยามที่เกี่ยวข้องกับ ทรี
1.นิยามทรีด้วยนิยามของกราฟ
ทรี คือ กราฟที่ต่อเนื่องโดยไม่มีวงจรปิด (loop) ในโครงสร้าง โหนดสองโหนดใดๆในทรีต้งมทางติดต่อกันทางเดียวเท่านั้น และทรีที่มี N โหนด ต้องมีกิ่งทั้งหมด N-1 เส้น อาจเขียนได้ 4 รูปแบบ
- แบบมีรากอยู่ด้านบน
- แบบมีรากอยู่ด้านล่าง
- แบบมีรากอยู่ด้านซ้าย
- แบบมีรากอยู่ด้านขวา
2. นิยามทรีด้วยรูปแบบรรีเคอร์ซีฟ
ทรีประกอบด้วยสมาชิกที่เรียกว่า โหนด โดยที่ ถ้าว่าง ไม่มีโหนดใดๆ เรียกว่า Null Tree และถ้ามีโหนดหนึ่งเป็นโหนดราก ส่วนที่เหลือจะแบ่งเป็น ทรีย่อย (Sub Tree) โดยที่ k>=0 และทรีย่อยต้องมีคุณสมบัติเป็นทรี
นิยามที่เกี่ยวข้อง
1.ฟอร์เรสต์ (Forest)
2.ทรีที่มีแบบแผน (Ordered Tree)
3.ทรีคล้าย (Similar Tree)
4.ทรีเหมือน (Equivalent Tree)
5.กำลัง(Degree)
6.ระดับของโหนด (Level of Node)
การแทนที่ทรีในหน่วยความจำหลัก
1.โหนดแต่ละโหนดเก็บพอยเตอร์ชี้ไปยังโหนดลูกทุกโหนด ซึ่งจะทำให้ฟิลด์มีจำนวนเท่ากัน มีขนาดเท่ากับโหนดที่มีลูกมากที่สุด โหนดที่ไม่มีลูกใส่ค่า Null แล้วให้ลิงค์ฟิลด์เก็บค่าพอยเตอร์ของโหนดลูกตัวถัดไปเรื่อยๆ เช่น ลิงค์ฟิลด์แรกเก็บค่าพอยเตอร์ชี้ไปยังโหนดลูกลำดับแรก แต่การแทนที่ทรีด้วยวิธีนี้เป็นการสิ้นเปลืองเนื้อที่โดยใช่เหตุเนื่องจากว่าโหนดบางโหนดอาจมีโหนดลูกน้อย หรือไม่มีโหนดลูกเลย
2.แทนทรีด้วยไบนารีทรี จะมีการกำหนดโหนดทุกโหนดให้มีจำนวนลิงค์ฟิลด์เพียงสองลิงค์ฟิลด์ โดยลิงค์ฟิลด์แรกเก็บที่อยู่โหนดลูกคนโต ลิงค์ฟิลด์ที่สองเก็บที่อยู่โหนดพี่น้อง กรณีไม่มีโหนดลูกและโหนดพี่น้องใส่ Null การแทนที่ทรีด้วยวินี้เป็นการประหยัดเนื้อที่ได้มาก
ไบนารีทรีแบบสมบูรณ์นั้นจะมีโหนดทรีย่อยทางด้านซ้ายและขวา ยกเว้นโหนดใบหรือโหนดที่ไม่มีลูก แต่โหนดใบจะต้องอยู่ในระดับเดียวกัน
การแปลงทรีทั่วไปให้เป็นไบนารีทรี มีขั้นตอนดังนี้
1.ให้โหนดแม่ชี้ไปยังโหนดลูกคนโตแล้วตัดความสัมพันธ์ระหว่างโหนดลูกอื่นๆ
2.เชื่อมความสัมพันธ์ระหว่างโหนดพี่น้อง
3.ให้ทรีย่อยทางขวาเอียงลงมา 45 องศา
การท่องไปในไบนารีทรี
เป็นการเยือนทุกๆโหนด อย่างมีระบบแบบแผน สามารถเยือนโหนดได้โหนดละหนึ่งครั้ง วิธีการท่องนั้นอยู่ที่ว่าต้องการลำดับการเยือนอย่างไร โดย
- N อาจเป็นโหนดแม่
- L ทรีย่อยทางซ้าย
- R ทรีย่อยทางขวา
วิธีการท่องไปในทรีมี 6 วิธี แต่นิยมใช้กันมากคือ NLR , LNR , LRN
1. การท่องไปแบบพรีออร์เดอร์ เป็นการเยือนด้วยวิธี NLR ในลักษณะการเข้าถึงจะเริ่มต้นจากจุดแรกคือ N จากนั้นจึงเข้าไปทรีย่อยด้านซ้ายและเข้าถึงทรีย่อยด้านขวา
2. การท่องไปแบบอินออร์เดอร์ เป็นการเยือนด้วยวิธี LNR สำหรับการเข้าถึงแบบอินออร์เดอร์จะดำเนินการเข้าเยี่ยมทรีย่อยด้านซ้ายก่อน จากนั้นจึงเข้าเยี่ยม N และสิ้นสุดการเข้าเยี่ยมที่ทรีย่อยด้านขวา
3. การท่องไปแบบโพสออร์เดอร์ เป็นการเยือนด้วยวิธี LRN การประมวลผลของโพสออร์เดอร์ จะเริ่มต้นด้วยทรีย่อยด้านซ้ายจานั้นมาประมวลผลต่อที่ทรีย่อยด้านขวาและสิ้นสุดการประมวลผลที่ N
ทรี (Tree) เป็นโครงสร้างข้อมูลที่มีความสัมพันธ์กัน ระหว่าง โหนดจะมีความสัมพันธ์ลดหลั่นกันเป็นลำดับชั้น ส่วนมากจะใช้สำหรับ แสดงความสัมพันธ์ระหว่างข้อมูล ในทรีหนึ่งทรีจะประกอบไปด้วยรูทโหนด (root node) เพียงหนึ่งโหนด แล้วรูทโหนดสามารถแตกโหนดออกเป็นโหนดย่อยๆ ได้อีกหลายโหนดเรียกว่าโหนดลูก (Child node) เมื่อมีโหนดลูกแล้ว โหนดลูกก็ยังสามารถแสดงเป็นโหนดพ่อแม่ (Parent Node) โดยการแตกโหนดออกเป็นโหนดย่อยๆได้อีก
นิยามของโครงสร้างต้นไม้
1. นิยามของทรีด้วยนิยามของกราฟ
2. นิยามทรีด้วยรูปแบบรีเคอร์ซีฟ
นิยามที่เกี่ยวข้องกับ ทรี
1.นิยามทรีด้วยนิยามของกราฟ
ทรี คือ กราฟที่ต่อเนื่องโดยไม่มีวงจรปิด (loop) ในโครงสร้าง โหนดสองโหนดใดๆในทรีต้งมทางติดต่อกันทางเดียวเท่านั้น และทรีที่มี N โหนด ต้องมีกิ่งทั้งหมด N-1 เส้น อาจเขียนได้ 4 รูปแบบ
- แบบมีรากอยู่ด้านบน
- แบบมีรากอยู่ด้านล่าง
- แบบมีรากอยู่ด้านซ้าย
- แบบมีรากอยู่ด้านขวา
2. นิยามทรีด้วยรูปแบบรรีเคอร์ซีฟ
ทรีประกอบด้วยสมาชิกที่เรียกว่า โหนด โดยที่ ถ้าว่าง ไม่มีโหนดใดๆ เรียกว่า Null Tree และถ้ามีโหนดหนึ่งเป็นโหนดราก ส่วนที่เหลือจะแบ่งเป็น ทรีย่อย (Sub Tree) โดยที่ k>=0 และทรีย่อยต้องมีคุณสมบัติเป็นทรี
นิยามที่เกี่ยวข้อง
1.ฟอร์เรสต์ (Forest)
2.ทรีที่มีแบบแผน (Ordered Tree)
3.ทรีคล้าย (Similar Tree)
4.ทรีเหมือน (Equivalent Tree)
5.กำลัง(Degree)
6.ระดับของโหนด (Level of Node)
การแทนที่ทรีในหน่วยความจำหลัก
1.โหนดแต่ละโหนดเก็บพอยเตอร์ชี้ไปยังโหนดลูกทุกโหนด ซึ่งจะทำให้ฟิลด์มีจำนวนเท่ากัน มีขนาดเท่ากับโหนดที่มีลูกมากที่สุด โหนดที่ไม่มีลูกใส่ค่า Null แล้วให้ลิงค์ฟิลด์เก็บค่าพอยเตอร์ของโหนดลูกตัวถัดไปเรื่อยๆ เช่น ลิงค์ฟิลด์แรกเก็บค่าพอยเตอร์ชี้ไปยังโหนดลูกลำดับแรก แต่การแทนที่ทรีด้วยวิธีนี้เป็นการสิ้นเปลืองเนื้อที่โดยใช่เหตุเนื่องจากว่าโหนดบางโหนดอาจมีโหนดลูกน้อย หรือไม่มีโหนดลูกเลย
2.แทนทรีด้วยไบนารีทรี จะมีการกำหนดโหนดทุกโหนดให้มีจำนวนลิงค์ฟิลด์เพียงสองลิงค์ฟิลด์ โดยลิงค์ฟิลด์แรกเก็บที่อยู่โหนดลูกคนโต ลิงค์ฟิลด์ที่สองเก็บที่อยู่โหนดพี่น้อง กรณีไม่มีโหนดลูกและโหนดพี่น้องใส่ Null การแทนที่ทรีด้วยวินี้เป็นการประหยัดเนื้อที่ได้มาก
ไบนารีทรีแบบสมบูรณ์นั้นจะมีโหนดทรีย่อยทางด้านซ้ายและขวา ยกเว้นโหนดใบหรือโหนดที่ไม่มีลูก แต่โหนดใบจะต้องอยู่ในระดับเดียวกัน
การแปลงทรีทั่วไปให้เป็นไบนารีทรี มีขั้นตอนดังนี้
1.ให้โหนดแม่ชี้ไปยังโหนดลูกคนโตแล้วตัดความสัมพันธ์ระหว่างโหนดลูกอื่นๆ
2.เชื่อมความสัมพันธ์ระหว่างโหนดพี่น้อง
3.ให้ทรีย่อยทางขวาเอียงลงมา 45 องศา
การท่องไปในไบนารีทรี
เป็นการเยือนทุกๆโหนด อย่างมีระบบแบบแผน สามารถเยือนโหนดได้โหนดละหนึ่งครั้ง วิธีการท่องนั้นอยู่ที่ว่าต้องการลำดับการเยือนอย่างไร โดย
- N อาจเป็นโหนดแม่
- L ทรีย่อยทางซ้าย
- R ทรีย่อยทางขวา
วิธีการท่องไปในทรีมี 6 วิธี แต่นิยมใช้กันมากคือ NLR , LNR , LRN
1. การท่องไปแบบพรีออร์เดอร์ เป็นการเยือนด้วยวิธี NLR ในลักษณะการเข้าถึงจะเริ่มต้นจากจุดแรกคือ N จากนั้นจึงเข้าไปทรีย่อยด้านซ้ายและเข้าถึงทรีย่อยด้านขวา
2. การท่องไปแบบอินออร์เดอร์ เป็นการเยือนด้วยวิธี LNR สำหรับการเข้าถึงแบบอินออร์เดอร์จะดำเนินการเข้าเยี่ยมทรีย่อยด้านซ้ายก่อน จากนั้นจึงเข้าเยี่ยม N และสิ้นสุดการเข้าเยี่ยมที่ทรีย่อยด้านขวา
3. การท่องไปแบบโพสออร์เดอร์ เป็นการเยือนด้วยวิธี LRN การประมวลผลของโพสออร์เดอร์ จะเริ่มต้นด้วยทรีย่อยด้านซ้ายจานั้นมาประมวลผลต่อที่ทรีย่อยด้านขวาและสิ้นสุดการประมวลผลที่ N
16.8.52
DTS 17-08-52
สรุปเนื้อหาบทเรียน เรื่อง Queue
โครงสร้างแบบ Queue
คิว เป็นโครงสร้างข้อมูลแบบลิเนียร์ลิสต์ ซึ่งการเพิ่มข้อมูลจะกระทำที่ปลายข้างหนึ่ง เรียกว่าส่วนท้ายหรือ เรียร์ (rear) และการนำข้อมูลออกจะกระทำที่ปลายอีกข้างหนึ่งเรียกว่าส่วนหน้าหรือ ฟรอนต์ (front)
ลัษณะการทำงานของคิว
เป็นลักษณะของการเข้าก่อนออกก่อน หรือที่เรียกว่า FIFO (First In First Out)จะเหมือนกับการเข้าแถวรอคอย ไม่ว่าจะเป็นการรอคอยอะไรก็ตาม หรือจะเรียกสั้นๆ ว่า เข้าคิวก็ได้
1.การใส่ข้อมูลตัวใหม่ลงในคิว เรียกว่า Enqueue ก่อนที่จะใส่ข้อมูลลงไปต้องตรวจสอบก่อนว่าคิวเต็มหรือไม่ ถ้าพยายามใส่ข้อมูลลงไปอาจเกิดข้อผิดพลาด ที่เรียกว่า overflow
2.การนำสมาชิกออกจากคิว เรียกว่า Dequeue จะไม่สามารถนำข้อมูลออกจากคิวที่ว่างได้ ถ้าพยายามนำข้อมูลออกอาจเกิดข้อผิดพลาดที่เรียกว่า underflow
3.การนำข้อมูลที่อยู่ตอนต้นของคิวหรือข้อมูลที่อยู่ลำดับแรกมาแสดง เรียกว่า Queue Front เพื่อรู้ว่าข้อมูลตัวต่อไปคืออะไร
4.การนำข้อมูลที่อยู่ตอนท้ายของคิว หรือข้อมูลที่เข้ามาตัวสุดท้ายมาแสดง เรียกว่า Queue Rear เพื่อรู้ว่าข้อมูลตัวสุดท้ายคืออะไร
การดำเนินการเกี่ยวกับคิว
1.Create Queue คือการสร้างคิวขึ้นมา แล้วจัดสรรหน่วยความจำให้กับ Head Node และพอยเตอร์มีค่าเป็น Null
2.Enqueue คือ การเพิ่มข้อมูลลงไปในคิวโดยการเพิ่มจะเพิ่มจากส่วนท้าย
3.Dequeue คือ การนำข้อมูลในคิวออก จะออกโดยข้อมูลที่เข้าไปตัวแรกจะออกก่อน
4.Queue Front คือ การนำข้อมูลตัวแรกที่เข้าไปในคิวออกมาแสดง
5.Queue Rear คือ การนำข้อมูลตัวสุดท้ายที่เข้ามาในคิวออกมาแสดง
6.Empty Queue คือ เป็นการตรวจสอบว่าคิวนั้นยังคงว่างอยู่หรือไม่
7.Full Queue คือ เป็นการตรวจสอบว่าคิวนั้นเต็มหรือไม่
8.Queue Count คือ เป็นการนับจำนวนข้อมูลที่อยูในคิว ว่ามีจำนวนเท่าไร
9.Destroy Queue คือ การลบข้อมูลที่อยูในคิวทิ้ง
การแทนที่ข้อมูลของคิว มี 2 วิธี คือ
1.การแทนที่ข้อมูลของคิวแบบอะเรย์ มีการกำหนดขนาดของคิวไว้ล่วงหน้าว่ามีขนาดเท่าไร และจะมีการจัดสรรเนื้อที่หน่วยความจำให้เลย เมื่อพื้นที่ของอะเรย์มีพื้นที่ว่าง อาจหมายความว่า พื้นที่ว่างนั้นเคยเก็บข้อมูลแล้วกับพื้นที่ว่างนั้นยังไม่เคยเก็บข้อมูลมาก่อน
*** กรณีที่ Front ไม่ได้อยู่ช่องแรก พื้นที่ว่างจะไม่สามารถใช้งานได้อีก จะแก้โดยใช้คิวแบบวงกลม คือ ช่องสุดท้ายต่อกับช่องแรก คิวแบบวงกลมจะเต็มก็ต่อเมื่อ rear มีค่าน้อยกว่า front
2.การแทนที่ข้อมูลของคิวแบบลิงค์ลิสต์ ประกอบไปด้วย 2 ส่วน คือ Head Node มี 3 ส่วนมีพอยเตอร์ 2 ตัว และจำนวนสมาชิก กับ Data Node จะมีข้อมูล และพอยเตอร์ชี้ตัวถัดไป
การประยุกต์ใช้คิว
จะถูกประยุกต์ใช้มากในระบบธุรกิจ เช่นการให้บริการลูกค้า คือลูกค้าที่มาก่อนย่อมต้องได้รับบริการก่อน และในด้านคอมพิวเตอร์ในระบบปฏิบัติงาน (Operating System) คือจัดให้งานที่เข้ามา ได้ทำงานตามความสำคัญ (Priority)
***เช่น สมมติว่า Priority มีงาน 3 ระดับ เรียงจากมากไปหาน้อยระบุโดยตัวเลข เลข 1 มากสุดเรื่อยไปจนถึง 3 น้อยสุด ถ้ามีงาน A,B,C เข้ามาขอใช้ CPU โดยมี Priority เป็น 4,2,1, ตามลำดับ ที่นี้งาน C จะถูกนำไปทำงานก่อน ตามด้วย B และ A
โครงสร้างแบบ Queue
คิว เป็นโครงสร้างข้อมูลแบบลิเนียร์ลิสต์ ซึ่งการเพิ่มข้อมูลจะกระทำที่ปลายข้างหนึ่ง เรียกว่าส่วนท้ายหรือ เรียร์ (rear) และการนำข้อมูลออกจะกระทำที่ปลายอีกข้างหนึ่งเรียกว่าส่วนหน้าหรือ ฟรอนต์ (front)
ลัษณะการทำงานของคิว
เป็นลักษณะของการเข้าก่อนออกก่อน หรือที่เรียกว่า FIFO (First In First Out)จะเหมือนกับการเข้าแถวรอคอย ไม่ว่าจะเป็นการรอคอยอะไรก็ตาม หรือจะเรียกสั้นๆ ว่า เข้าคิวก็ได้
1.การใส่ข้อมูลตัวใหม่ลงในคิว เรียกว่า Enqueue ก่อนที่จะใส่ข้อมูลลงไปต้องตรวจสอบก่อนว่าคิวเต็มหรือไม่ ถ้าพยายามใส่ข้อมูลลงไปอาจเกิดข้อผิดพลาด ที่เรียกว่า overflow
2.การนำสมาชิกออกจากคิว เรียกว่า Dequeue จะไม่สามารถนำข้อมูลออกจากคิวที่ว่างได้ ถ้าพยายามนำข้อมูลออกอาจเกิดข้อผิดพลาดที่เรียกว่า underflow
3.การนำข้อมูลที่อยู่ตอนต้นของคิวหรือข้อมูลที่อยู่ลำดับแรกมาแสดง เรียกว่า Queue Front เพื่อรู้ว่าข้อมูลตัวต่อไปคืออะไร
4.การนำข้อมูลที่อยู่ตอนท้ายของคิว หรือข้อมูลที่เข้ามาตัวสุดท้ายมาแสดง เรียกว่า Queue Rear เพื่อรู้ว่าข้อมูลตัวสุดท้ายคืออะไร
การดำเนินการเกี่ยวกับคิว
1.Create Queue คือการสร้างคิวขึ้นมา แล้วจัดสรรหน่วยความจำให้กับ Head Node และพอยเตอร์มีค่าเป็น Null
2.Enqueue คือ การเพิ่มข้อมูลลงไปในคิวโดยการเพิ่มจะเพิ่มจากส่วนท้าย
3.Dequeue คือ การนำข้อมูลในคิวออก จะออกโดยข้อมูลที่เข้าไปตัวแรกจะออกก่อน
4.Queue Front คือ การนำข้อมูลตัวแรกที่เข้าไปในคิวออกมาแสดง
5.Queue Rear คือ การนำข้อมูลตัวสุดท้ายที่เข้ามาในคิวออกมาแสดง
6.Empty Queue คือ เป็นการตรวจสอบว่าคิวนั้นยังคงว่างอยู่หรือไม่
7.Full Queue คือ เป็นการตรวจสอบว่าคิวนั้นเต็มหรือไม่
8.Queue Count คือ เป็นการนับจำนวนข้อมูลที่อยูในคิว ว่ามีจำนวนเท่าไร
9.Destroy Queue คือ การลบข้อมูลที่อยูในคิวทิ้ง
การแทนที่ข้อมูลของคิว มี 2 วิธี คือ
1.การแทนที่ข้อมูลของคิวแบบอะเรย์ มีการกำหนดขนาดของคิวไว้ล่วงหน้าว่ามีขนาดเท่าไร และจะมีการจัดสรรเนื้อที่หน่วยความจำให้เลย เมื่อพื้นที่ของอะเรย์มีพื้นที่ว่าง อาจหมายความว่า พื้นที่ว่างนั้นเคยเก็บข้อมูลแล้วกับพื้นที่ว่างนั้นยังไม่เคยเก็บข้อมูลมาก่อน
*** กรณีที่ Front ไม่ได้อยู่ช่องแรก พื้นที่ว่างจะไม่สามารถใช้งานได้อีก จะแก้โดยใช้คิวแบบวงกลม คือ ช่องสุดท้ายต่อกับช่องแรก คิวแบบวงกลมจะเต็มก็ต่อเมื่อ rear มีค่าน้อยกว่า front
2.การแทนที่ข้อมูลของคิวแบบลิงค์ลิสต์ ประกอบไปด้วย 2 ส่วน คือ Head Node มี 3 ส่วนมีพอยเตอร์ 2 ตัว และจำนวนสมาชิก กับ Data Node จะมีข้อมูล และพอยเตอร์ชี้ตัวถัดไป
การประยุกต์ใช้คิว
จะถูกประยุกต์ใช้มากในระบบธุรกิจ เช่นการให้บริการลูกค้า คือลูกค้าที่มาก่อนย่อมต้องได้รับบริการก่อน และในด้านคอมพิวเตอร์ในระบบปฏิบัติงาน (Operating System) คือจัดให้งานที่เข้ามา ได้ทำงานตามความสำคัญ (Priority)
***เช่น สมมติว่า Priority มีงาน 3 ระดับ เรียงจากมากไปหาน้อยระบุโดยตัวเลข เลข 1 มากสุดเรื่อยไปจนถึง 3 น้อยสุด ถ้ามีงาน A,B,C เข้ามาขอใช้ CPU โดยมี Priority เป็น 4,2,1, ตามลำดับ ที่นี้งาน C จะถูกนำไปทำงานก่อน ตามด้วย B และ A
4.8.52
DTS 29-07-2552
stack (ต่อ)
การดำเนินการเกี่ยวกับสแตกการดำเนินการเกี่ยวกับสแตก
ได้แก่
1. Create Stack จัดสรรหน่วยความจำให้แก่ Head Nodeและส่งค่าตำแหน่งที่ชี้ไปยัง Head ของสแตกกลับมา
2.Push Stack การเพิ่มข้อมูลลงไปในสแตก
3.Pop stack การนำข้อมูลบนสุดออกจากสแตก
4. Stack Top เป็นการคัดลอกข้อมูลที่อยู่บนสุดของสแตกโดยไม่มีการลบข้อมูลออกจากสแตก
5.Empty Stack เป็นการตรวจสอบการวางของสแตกเพื่อไม่ให้เกิดความผิดพลาดในการนำข้อมูลออกจากสแตกที่เรียกว่า Stack Underflow
6. Full Stack เป็นการตรวจสอบว่าสแตกเต็มหรือไม่เพื่อไม่ให้เกิดความผิดพลาดในการนำข้อมูลเข้าสแตกที่เรียกว่า Stack Overflow
7. Stack Count เป็นการนับจำนวนสมาชิกในสแตก
8.Destroy Stack เป็นการลบข้อมูลทั้งหมดที่อยู่ใน สแตก8.Destroy Stack เป็นการลบข้อมูลทั้งหมดที่อยู่ใน สแตก
ขั้นตอนการแปลงจากนิพจน์ Infix เป็นนิพจน์ Postfix
1. อ่านอักขระในนิพจน์ Infix เข้ามาทีละตัว
2. ถ้าเป็นตัวถูกดำเนินการจะถูกย้ายไปเป็นตัวอักษรในนิพจน์ Postfix
3. ถ้าเป็นตัวดำเนินการ จะนำค่าลำดับความสำคัญของตัว ดำเนินการที่อ่านเข้ามาเทียบกับค่าลำดับความสำคัญของตัวดำเนินการที่อยู่บนสุดของสแตก
- ถ้ามีความสำคัญมากกว่า จะถูก push ลงในสแตก
- ถ้ามีความสำคัญน้อยกว่าหรือเท่ากัน จะต้อง pop ตัวดำเนินการที่อยู่ในสแตกขณะนั้นไปเรียงต่อกับตัวอักษรในนิพจน์ Postfix
4. ตัวดำเนินการที่เป็นวงเล็บปิด “)” จะไม่ push ลงในสแตกแต่มีผลให้ตัวดำเนินการอื่น ๆ ถูก pop ออกจากสแตกนำไป เรียงต่อกันในนิพจน์ Postfix จนกว่าจะเจอ “(” จะ popวงเล็บเปิดออกจากสแตกแต่ไม่นำไปเรียงต่อ
5. เมื่อทำการอ่านตัวอักษรในนิพจน์ Infix หมดแล้ว ให้ทำการ Pop ตัวดำเนินการทุกตัวในสแตกนำมาเรียงต่อในนิพจน์Postfix
การดำเนินการเกี่ยวกับสแตกการดำเนินการเกี่ยวกับสแตก
ได้แก่
1. Create Stack จัดสรรหน่วยความจำให้แก่ Head Nodeและส่งค่าตำแหน่งที่ชี้ไปยัง Head ของสแตกกลับมา
2.Push Stack การเพิ่มข้อมูลลงไปในสแตก
3.Pop stack การนำข้อมูลบนสุดออกจากสแตก
4. Stack Top เป็นการคัดลอกข้อมูลที่อยู่บนสุดของสแตกโดยไม่มีการลบข้อมูลออกจากสแตก
5.Empty Stack เป็นการตรวจสอบการวางของสแตกเพื่อไม่ให้เกิดความผิดพลาดในการนำข้อมูลออกจากสแตกที่เรียกว่า Stack Underflow
6. Full Stack เป็นการตรวจสอบว่าสแตกเต็มหรือไม่เพื่อไม่ให้เกิดความผิดพลาดในการนำข้อมูลเข้าสแตกที่เรียกว่า Stack Overflow
7. Stack Count เป็นการนับจำนวนสมาชิกในสแตก
8.Destroy Stack เป็นการลบข้อมูลทั้งหมดที่อยู่ใน สแตก8.Destroy Stack เป็นการลบข้อมูลทั้งหมดที่อยู่ใน สแตก
ขั้นตอนการแปลงจากนิพจน์ Infix เป็นนิพจน์ Postfix
1. อ่านอักขระในนิพจน์ Infix เข้ามาทีละตัว
2. ถ้าเป็นตัวถูกดำเนินการจะถูกย้ายไปเป็นตัวอักษรในนิพจน์ Postfix
3. ถ้าเป็นตัวดำเนินการ จะนำค่าลำดับความสำคัญของตัว ดำเนินการที่อ่านเข้ามาเทียบกับค่าลำดับความสำคัญของตัวดำเนินการที่อยู่บนสุดของสแตก
- ถ้ามีความสำคัญมากกว่า จะถูก push ลงในสแตก
- ถ้ามีความสำคัญน้อยกว่าหรือเท่ากัน จะต้อง pop ตัวดำเนินการที่อยู่ในสแตกขณะนั้นไปเรียงต่อกับตัวอักษรในนิพจน์ Postfix
4. ตัวดำเนินการที่เป็นวงเล็บปิด “)” จะไม่ push ลงในสแตกแต่มีผลให้ตัวดำเนินการอื่น ๆ ถูก pop ออกจากสแตกนำไป เรียงต่อกันในนิพจน์ Postfix จนกว่าจะเจอ “(” จะ popวงเล็บเปิดออกจากสแตกแต่ไม่นำไปเรียงต่อ
5. เมื่อทำการอ่านตัวอักษรในนิพจน์ Infix หมดแล้ว ให้ทำการ Pop ตัวดำเนินการทุกตัวในสแตกนำมาเรียงต่อในนิพจน์Postfix
28.7.52


22.7.52
DTS 22-07-52
stack
สแตกเป็นโครงสร้างข้อมูลแบบลิเนียร์ลิสต์(linear list) ที่สามารถนำข้อมูลเข้าหรือออกได้ทางเดียว คือ ส่วนบนของสแตกหรือ เรียกว่า ท๊อปของสแตก (Top Of Stack) ซึ่งคุณสมบัติดังกล่าวเรียกว่า ไลโฟลิสต์ (LIFO list: Last-In-First-Out list) หรือ พูชดาวน์ลิสต์ (Pushdown List) คือสมาชิกที่เข้าลิสต์ที่หลังสุดจะได้ออกจากลิสต์ก่อน หรือ เข้าหลังออกก่อน การเพิ่มข้อมูลเข้าสแตกจะเรียกว่าพูชชิ่ง (pushing) การนำข้อมูลจากสแตกเรียกว่า ป๊อปปิ้ง (poping) การเพิ่มหรือลบข้อมูลในสแตกทำที่ท๊อปของสแตก ท๊อปของสแตกนี้เองเป็นตัวชี้สมาชิกตัวท้ายสุดของสแตก
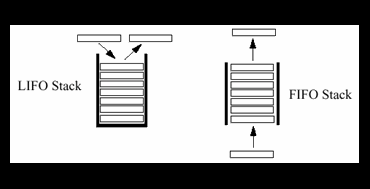
ส่วนประกอบของสแตก
การนำสแตกไปใช้งานนั้น ไม่ว่าจะเป็นโครงสร้างสแตกแบบแถวลำดับ(array)หรือ แบบลิงค์ลิสต์ (link list) เราจะมีตัวแปรตัวหนึ่งที่ใช้เป็นตัวชี้สแตก(stack pointer ) เพื่อเป็นตัวชี้ข้อมูลที่อยู่บนสุดของสแตก ซึ่งจะทำให้สามารถจัดการข้อมูล ที่จะเก็บในสแตกได้ง่าย ดังนั้นโครงสร้างข้อมูลแบบสแตกจะแบ่งออกเป็น 2 ส่วนที่สำคัญ คือ
ตัวชี้สแตก ( Stack Pointer ) ซึ่งมีหน้าที่ชี้ไปยังข้อมูลที่อยู่บนสุดของ สแตก ( Top stack )
สมาชิกของสแตก ( Stack Element ) เป็นข้อมูลที่จะเก็บลงไปในสแตก ซึ่งจะต้องเป็นข้อมูลชนิด
เดียวกัน เช่น ข้อมูลชนิดจำนวนเต็ม เป็นต้น
การจัดการ กับสแตก
ในการทำงานของสแตก ประกอบด้วย 2 กระบวนการ คือ
1. การเพิ่มข้อมูลในสแตก (pushing stack) เป็นการนำข้อมูลเข้าสู่สแตก ซึ่งการกระทำเช่นนี้ เราเรียกว่า push ซึ่งโดยปกติก่อนที่จะนำข้อมูลเก็บลงในสแตกจะต้องมีการตรวจสอบพื้นที่ในสแตกก่อน ว่ามีที่เหลือว่างให้เก็บข้อมูลได้อีกหรือไม่
2. การดึงข้อมูลจากสแตก (Popping Stack) หมายถึงการเอาข้อมูลที่อยู่บนสุดในสแตก หรือที่ชี้ด้วย ท๊อปออกจากสแตก เรียกว่าการ pop ในการpop นั้นเราจะสามารถ pop ข้อมูลจากสแตกได้เรื่อย ๆ จนกว่า ข้อมูลจะหมดสแตก หรือ เป็นสแตกว่าง โดยก่อนที่จะนำข้อมูลออกจากสแตก จะต้องมีการตรวจสอบว่าใน สแตกมีข้อมูลเก็บ อยู่หรือไม่
ปัญหาที่เกิดขึ้นกับสแตก
1.สแตกเต็ม (Full Stack) การ push สแตกทุกครั้งจะมีการตรวจสอบที่ว่างในสแตกว่ามีที่ว่างเหลือหรือไม่ ถ้าไม่มีที่ว่างเหลืออยู่ เราก็จะไม่สามารถทำการ push สแตกได้ ในกรณีเช่นนี้เราเรียกว่าเกิดสถานะล้นเต็ม (Stack Overflow) โดย การตรวจสอบว่าสแตกเต็มหรือไม่ เราจะใช้ตัวชี้สแตก (Stack pointer) มาเปรียบเทียบกับค่าสูงสุดของ สแตก (Max stack) หากตัวชี้สแตกมีค่าเท่ากับค่าสูงสุดของสแตกแล้ว แสดงว่าไม่มีที่ว่างให้ข้อเก็บข้อมูล อีก
2. สแตกว่าง (Empty Stack) นิยาม empty(S) ถ้า S เป็นสแตก ขบวนการ empty(S) จะส่งผลเป็นจริง (true) เมื่อสแตกว่าง และส่งผลเป็นเท็จ (false) เมื่อสแตกไม่ว่างหรือสแตกเต็ม
การ pop สแตกทุกครั้งจะมีการตรวจสอบข้อมูลในสแตกว่ามีข้อมูลในสแตกหรือไม่ ถ้าไม่มีข้อมูลในสแตก เหลืออยู่ เราก็ไม่สามารถทำการ pop สแตกได้ ในกรณีเช่นนี้เรียกว่าเกิดสถานะ สแตกจม (Stack Underflow) โดยการตรวจสอบว่าสแตกว่างหรือไม่ เราจะตรวจสอบตัวชี้สแตกว่าเท่ากับ 0 หรือ null หรือไม่ ถ้าเท่ากับ 0 แสดงว่า สแตกว่าง จึงไม่สามารถดึงข้อมูลออกจากสแตกได้
ยกตัวอย่างการทำงานแบบ LIFO
รูปแสดงลักษณะของสแตค ที่ประกอบด้วยข้อมูล A , B , C , D และ E มี TOP ที่ชี้ที่สมาชิกตัวบนสุดของสแตค
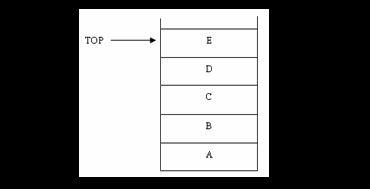
การเข้าทีหลังออกก่อน
ตัวอย่างเช่น เก้าอี้ที่วางซ้อนกัน
สแตกเป็นโครงสร้างข้อมูลแบบลิเนียร์ลิสต์(linear list) ที่สามารถนำข้อมูลเข้าหรือออกได้ทางเดียว คือ ส่วนบนของสแตกหรือ เรียกว่า ท๊อปของสแตก (Top Of Stack) ซึ่งคุณสมบัติดังกล่าวเรียกว่า ไลโฟลิสต์ (LIFO list: Last-In-First-Out list) หรือ พูชดาวน์ลิสต์ (Pushdown List) คือสมาชิกที่เข้าลิสต์ที่หลังสุดจะได้ออกจากลิสต์ก่อน หรือ เข้าหลังออกก่อน การเพิ่มข้อมูลเข้าสแตกจะเรียกว่าพูชชิ่ง (pushing) การนำข้อมูลจากสแตกเรียกว่า ป๊อปปิ้ง (poping) การเพิ่มหรือลบข้อมูลในสแตกทำที่ท๊อปของสแตก ท๊อปของสแตกนี้เองเป็นตัวชี้สมาชิกตัวท้ายสุดของสแตก

ส่วนประกอบของสแตก
การนำสแตกไปใช้งานนั้น ไม่ว่าจะเป็นโครงสร้างสแตกแบบแถวลำดับ(array)หรือ แบบลิงค์ลิสต์ (link list) เราจะมีตัวแปรตัวหนึ่งที่ใช้เป็นตัวชี้สแตก(stack pointer ) เพื่อเป็นตัวชี้ข้อมูลที่อยู่บนสุดของสแตก ซึ่งจะทำให้สามารถจัดการข้อมูล ที่จะเก็บในสแตกได้ง่าย ดังนั้นโครงสร้างข้อมูลแบบสแตกจะแบ่งออกเป็น 2 ส่วนที่สำคัญ คือ
ตัวชี้สแตก ( Stack Pointer ) ซึ่งมีหน้าที่ชี้ไปยังข้อมูลที่อยู่บนสุดของ สแตก ( Top stack )
สมาชิกของสแตก ( Stack Element ) เป็นข้อมูลที่จะเก็บลงไปในสแตก ซึ่งจะต้องเป็นข้อมูลชนิด
เดียวกัน เช่น ข้อมูลชนิดจำนวนเต็ม เป็นต้น
การจัดการ กับสแตก
ในการทำงานของสแตก ประกอบด้วย 2 กระบวนการ คือ
1. การเพิ่มข้อมูลในสแตก (pushing stack) เป็นการนำข้อมูลเข้าสู่สแตก ซึ่งการกระทำเช่นนี้ เราเรียกว่า push ซึ่งโดยปกติก่อนที่จะนำข้อมูลเก็บลงในสแตกจะต้องมีการตรวจสอบพื้นที่ในสแตกก่อน ว่ามีที่เหลือว่างให้เก็บข้อมูลได้อีกหรือไม่
2. การดึงข้อมูลจากสแตก (Popping Stack) หมายถึงการเอาข้อมูลที่อยู่บนสุดในสแตก หรือที่ชี้ด้วย ท๊อปออกจากสแตก เรียกว่าการ pop ในการpop นั้นเราจะสามารถ pop ข้อมูลจากสแตกได้เรื่อย ๆ จนกว่า ข้อมูลจะหมดสแตก หรือ เป็นสแตกว่าง โดยก่อนที่จะนำข้อมูลออกจากสแตก จะต้องมีการตรวจสอบว่าใน สแตกมีข้อมูลเก็บ อยู่หรือไม่
ปัญหาที่เกิดขึ้นกับสแตก
1.สแตกเต็ม (Full Stack) การ push สแตกทุกครั้งจะมีการตรวจสอบที่ว่างในสแตกว่ามีที่ว่างเหลือหรือไม่ ถ้าไม่มีที่ว่างเหลืออยู่ เราก็จะไม่สามารถทำการ push สแตกได้ ในกรณีเช่นนี้เราเรียกว่าเกิดสถานะล้นเต็ม (Stack Overflow) โดย การตรวจสอบว่าสแตกเต็มหรือไม่ เราจะใช้ตัวชี้สแตก (Stack pointer) มาเปรียบเทียบกับค่าสูงสุดของ สแตก (Max stack) หากตัวชี้สแตกมีค่าเท่ากับค่าสูงสุดของสแตกแล้ว แสดงว่าไม่มีที่ว่างให้ข้อเก็บข้อมูล อีก
2. สแตกว่าง (Empty Stack) นิยาม empty(S) ถ้า S เป็นสแตก ขบวนการ empty(S) จะส่งผลเป็นจริง (true) เมื่อสแตกว่าง และส่งผลเป็นเท็จ (false) เมื่อสแตกไม่ว่างหรือสแตกเต็ม
การ pop สแตกทุกครั้งจะมีการตรวจสอบข้อมูลในสแตกว่ามีข้อมูลในสแตกหรือไม่ ถ้าไม่มีข้อมูลในสแตก เหลืออยู่ เราก็ไม่สามารถทำการ pop สแตกได้ ในกรณีเช่นนี้เรียกว่าเกิดสถานะ สแตกจม (Stack Underflow) โดยการตรวจสอบว่าสแตกว่างหรือไม่ เราจะตรวจสอบตัวชี้สแตกว่าเท่ากับ 0 หรือ null หรือไม่ ถ้าเท่ากับ 0 แสดงว่า สแตกว่าง จึงไม่สามารถดึงข้อมูลออกจากสแตกได้
ยกตัวอย่างการทำงานแบบ LIFO
รูปแสดงลักษณะของสแตค ที่ประกอบด้วยข้อมูล A , B , C , D และ E มี TOP ที่ชี้ที่สมาชิกตัวบนสุดของสแตค

การเข้าทีหลังออกก่อน
ตัวอย่างเช่น เก้าอี้ที่วางซ้อนกัน
21.7.52
DTS 21-07-52
สรุปบทเรียน Linked list
โครงสร้างข้อมูลแบบลิงค์ลิสต์ (Linked list)
โครงสร้างข้อมูลแบบนี้ จะให้ความสะดวกแก่การจัดการข้อมูลมาก อย่างไรก็ดีในบางครั้งก็ให้ความยุ่งยากแก่ผู้ใช้เนื่องจากจะซับซ้อนกว่าแบบใช้อาร์เรย์ ข้อจำกัดของการใช้อาร์เรย์คืออาร์เรย์มีขนาดคงที่ ถ้าเราจะใช้อาร์เรย์ขนาด 100 ช่อง เมื่อใช้หมด 100 ช่องก็ใช้อาร์เรย์นั้นไม่ได้ ถ้าไม่อนุญาตให้เคลียร์พื้นที่อาร์เาย์เพื่อใช้ซ้ำถึงแม้อนุญาตให้เคลียร์พื้นที่อาร์เรย์เพื่อใช้ซ้ำก็ไม่เป็นการสะดวก เนื่องจากอาจต้องตรวจทุกช่องในอาร์เรย์เพื่อหาว่าช่องไหนสามารถใช้ซ้ำได้ นอกจากนี้การใช้พื้นที่ซ้ำยังต้องเลื่อนข่าวสารทั้งหมดไปอยู่ในส่วนอาร์เรย์อีกประการคือ ในภาวะการทำงานแบบ real - time ที่ต้องมีการนำข้อมูลเข้า (insertion) หรือดึงข้อมูลออก (deletion) อาร์เรย์จะไม่สะดวกแก่การใช้มาก ในภาวะการทำงานแบบนี้โครงสร้างแบบลิงค์ลิสต์จะสะดวกกว่า การแทนแบบใช้พอยเตอร์นี้เราต้องใช้พื้นที่เพิ่มเติมเป็นส่วนของพอยน์เตอร์ (pointer) หรือลิงค์ (link) เพื่อแสดงให้เห็นขัดว่าโหนดที่ต่อจากโหนดนั้นคือโหนดใด ลักษณะของแต่ละโหนดจึงประกอบด้วยช่อง 2 ช่อง
ประเภทของ Linked list
1. แบบทิศทางเดียว
2. แบบสองทิศทาง
3. แบบวงกลม
4. แบบหลายทิศทาง
โครงสร้างของ Linked list มี 2 ส่วนใหญ่ๆ คือ
1. โครงสร้าง Head Node
2. โครงสร้าง Data Node
ลิงค์ลิสต์เดี่ยว (Singly Linked List)
ลิงค์ลิสต์เดี่ยว หมายถึง ลิงค์ลิสต์ที่แต่ละข่าวสารมีการแสดงออกถึงลำดับก่อนหลังอย่างชัดเจนโดยใช้พอยน์เตอร์ นั่นคือในแต่ละข่าวสารจะมีส่วนที่บอกว่าข่าวสารตัวต่อไปอยู่ที่ใด แต่ละข่าวสารจะเรียกว่าโหนด (node) แต่ละโหนดจะมี 2 ช่อง ดูรูปที่ 1 เป็นตัวอย่าง เราจะใช้สัญลักษณ์ต่อไปนี้ในการเรียกชื่อแต่ละโหนด
NODE(P) หมายถึง โหนดที่ระบุ(ถูกชี้) โดยพอยน์เตอร์ P
INFO(P) หมายถึง ส่วนข่าวสารของโหนดที่ถูกชี้โดย P
LINK(P) หมายถึง ส่วนแอดเดรสของโหนดที่ถูกชี้ P
ลิงค์ลิสต์คู่ (Doubly Linked List)
ลิงค์ลิสต์คู่ (Doubly Linked List) ลิงค์ลิสต์แบบนี้เป็นลิงค์ลิสต์ที่แต่ละโหนดมีสองพอยน์เตอร์คือ LLINK และ RLINK ซึ่งจะชี้ไปยังโหนดข้างซ้ายและข้างขวาของโหนดนั้นตามลำดับ ตัวอย่างเช่น ถ้าต้องการจะเก็บค่า A,B,C,D ในลิงค์ลิสต์ชนิดนี้จะได้โครงสร้างซึ่งปลายทั้งสองข้างของลิงค์ลิสต์ชนิดนี้จะมีพอยน์เตอร์ F และ R แสดงถึงโหนดแรกในทิศนั้น ถ้าใช้อาร์เรย์สร้างลิงค์ลิสต์ตามรูปที่ 19 จะต้องใช้อาร์เรย์ 3 ชุดคือ อาร์เรย์สำหรับช่องข่าวสาร (INFO) , อาร์เรย์สำหรับพอยน์เตอร์ทางซ้าย (LLINK) และอาร์เรย์สำหรับพอยน์เตอร์ทางขวา (RLINK)
เมื่อเปรียบเทียบลิงค์ลิสต์คู่กับลิงค์ลิสต์เดี่ยว จะเห็นได้ชัดว่าลิงค์ลิสต์คู่ต้องใช้เนื้อที่มากกว่า เนื่องจากต้องใช้ 2 พอยน์เตอรืสำหรับแต่ละโหนดแน่นอน ที่เสียไปนั้นก็เพื่อที่จะได้สิ่งบางอย่างเพิ่มเติม นั่นคือ ความสะดวกในการนำข่าวสารเข้าหรือออกจากลิงค์ลิสต์ ในกรณีลิงค์ลิสต์คู่ เราสามารถนำโหนดใหม่เข้าทาง ด้านหน้า หรือ ด้านหลังโหนด H1 ในลิงค์ลิสต์นั้นได้ นอกจากนี้เรายังสามารถคืนโหนด H1 ไปสู่ storage pool โดยตรงได้อีกด้วย อย่าลืมว่าเราไม่สามารถคืนโหนด H1 ไปสู่ storage pool ในกรณีลิงค์ลิสต์เดี่ยว
โครงสร้างข้อมูลแบบลิงค์ลิสต์ (Linked list)
โครงสร้างข้อมูลแบบนี้ จะให้ความสะดวกแก่การจัดการข้อมูลมาก อย่างไรก็ดีในบางครั้งก็ให้ความยุ่งยากแก่ผู้ใช้เนื่องจากจะซับซ้อนกว่าแบบใช้อาร์เรย์ ข้อจำกัดของการใช้อาร์เรย์คืออาร์เรย์มีขนาดคงที่ ถ้าเราจะใช้อาร์เรย์ขนาด 100 ช่อง เมื่อใช้หมด 100 ช่องก็ใช้อาร์เรย์นั้นไม่ได้ ถ้าไม่อนุญาตให้เคลียร์พื้นที่อาร์เาย์เพื่อใช้ซ้ำถึงแม้อนุญาตให้เคลียร์พื้นที่อาร์เรย์เพื่อใช้ซ้ำก็ไม่เป็นการสะดวก เนื่องจากอาจต้องตรวจทุกช่องในอาร์เรย์เพื่อหาว่าช่องไหนสามารถใช้ซ้ำได้ นอกจากนี้การใช้พื้นที่ซ้ำยังต้องเลื่อนข่าวสารทั้งหมดไปอยู่ในส่วนอาร์เรย์อีกประการคือ ในภาวะการทำงานแบบ real - time ที่ต้องมีการนำข้อมูลเข้า (insertion) หรือดึงข้อมูลออก (deletion) อาร์เรย์จะไม่สะดวกแก่การใช้มาก ในภาวะการทำงานแบบนี้โครงสร้างแบบลิงค์ลิสต์จะสะดวกกว่า การแทนแบบใช้พอยเตอร์นี้เราต้องใช้พื้นที่เพิ่มเติมเป็นส่วนของพอยน์เตอร์ (pointer) หรือลิงค์ (link) เพื่อแสดงให้เห็นขัดว่าโหนดที่ต่อจากโหนดนั้นคือโหนดใด ลักษณะของแต่ละโหนดจึงประกอบด้วยช่อง 2 ช่อง
ประเภทของ Linked list
1. แบบทิศทางเดียว
2. แบบสองทิศทาง
3. แบบวงกลม
4. แบบหลายทิศทาง
โครงสร้างของ Linked list มี 2 ส่วนใหญ่ๆ คือ
1. โครงสร้าง Head Node
2. โครงสร้าง Data Node
ลิงค์ลิสต์เดี่ยว (Singly Linked List)
ลิงค์ลิสต์เดี่ยว หมายถึง ลิงค์ลิสต์ที่แต่ละข่าวสารมีการแสดงออกถึงลำดับก่อนหลังอย่างชัดเจนโดยใช้พอยน์เตอร์ นั่นคือในแต่ละข่าวสารจะมีส่วนที่บอกว่าข่าวสารตัวต่อไปอยู่ที่ใด แต่ละข่าวสารจะเรียกว่าโหนด (node) แต่ละโหนดจะมี 2 ช่อง ดูรูปที่ 1 เป็นตัวอย่าง เราจะใช้สัญลักษณ์ต่อไปนี้ในการเรียกชื่อแต่ละโหนด
NODE(P) หมายถึง โหนดที่ระบุ(ถูกชี้) โดยพอยน์เตอร์ P
INFO(P) หมายถึง ส่วนข่าวสารของโหนดที่ถูกชี้โดย P
LINK(P) หมายถึง ส่วนแอดเดรสของโหนดที่ถูกชี้ P
ลิงค์ลิสต์คู่ (Doubly Linked List)
ลิงค์ลิสต์คู่ (Doubly Linked List) ลิงค์ลิสต์แบบนี้เป็นลิงค์ลิสต์ที่แต่ละโหนดมีสองพอยน์เตอร์คือ LLINK และ RLINK ซึ่งจะชี้ไปยังโหนดข้างซ้ายและข้างขวาของโหนดนั้นตามลำดับ ตัวอย่างเช่น ถ้าต้องการจะเก็บค่า A,B,C,D ในลิงค์ลิสต์ชนิดนี้จะได้โครงสร้างซึ่งปลายทั้งสองข้างของลิงค์ลิสต์ชนิดนี้จะมีพอยน์เตอร์ F และ R แสดงถึงโหนดแรกในทิศนั้น ถ้าใช้อาร์เรย์สร้างลิงค์ลิสต์ตามรูปที่ 19 จะต้องใช้อาร์เรย์ 3 ชุดคือ อาร์เรย์สำหรับช่องข่าวสาร (INFO) , อาร์เรย์สำหรับพอยน์เตอร์ทางซ้าย (LLINK) และอาร์เรย์สำหรับพอยน์เตอร์ทางขวา (RLINK)
เมื่อเปรียบเทียบลิงค์ลิสต์คู่กับลิงค์ลิสต์เดี่ยว จะเห็นได้ชัดว่าลิงค์ลิสต์คู่ต้องใช้เนื้อที่มากกว่า เนื่องจากต้องใช้ 2 พอยน์เตอรืสำหรับแต่ละโหนดแน่นอน ที่เสียไปนั้นก็เพื่อที่จะได้สิ่งบางอย่างเพิ่มเติม นั่นคือ ความสะดวกในการนำข่าวสารเข้าหรือออกจากลิงค์ลิสต์ ในกรณีลิงค์ลิสต์คู่ เราสามารถนำโหนดใหม่เข้าทาง ด้านหน้า หรือ ด้านหลังโหนด H1 ในลิงค์ลิสต์นั้นได้ นอกจากนี้เรายังสามารถคืนโหนด H1 ไปสู่ storage pool โดยตรงได้อีกด้วย อย่าลืมว่าเราไม่สามารถคืนโหนด H1 ไปสู่ storage pool ในกรณีลิงค์ลิสต์เดี่ยว
13.7.52
DTS 12-07-52
สรุปบทเรียน Pointer , Set and String
Pointer
คือ ตัวแปรที่เก็บตำแหน่งของหน่วยความจำ (memory address) ซึ่งตำแหน่งของหน่วยความจำนี้จะเป็นที่อยู่ของสิ่งอื่น ๆ (โดยทั่วไปจะเป็นตัวแปรอื่น) ในหน่วยความจำ เช่น ถ้าตัวแปรตัวหนึ่งเก็บตำแหน่งของตัวแปรอีกตัว เราอาจกล่าวได้ว่าตัวแปรตัวแรกนั้นชี้ไปยัง (point to) ตัวแปรที่สอง จะเก็บ Address ของตัวแปร แทนที่จะเก็บข้อมูลต่างๆ เหมือนตัวแปรชนิดอื่นๆ จากคุณสมบุติของ ตัวแปรชนิด Pointer จึงมองดูเหมือนกับ ตัวชี้ หรือพอยน์เตอร์ ซึ่งชี้ไปที่ Address ของตัวแปร
การกำหนดตัวแปร Pointer
จะคล้ายกับการกำหนดตัวแปรชนิดต่างๆ เพียงแต่ต้องมีเครื่องหมาย * หน้าชื่อตัวแปร ดังนี้
int *pt;
ในที่นี้กำหนดให้ pt เป็นตัวแปร Pointer ซึ่งเก็บ Address ของตัวแปรชนิดตัวเลขจำนวนเต็ม ในเรื่อง Pointer มีเครื่องหมาย 2 ชนิด คือ * และ & เครื่องหมาย * จะให้ค่า ของข้อมูล ซึ่งเก็บอยู่ใน Address โดย Address นี้เก็บ อยู่ในตัวแปร Pointer ซึ่งอยู่หลังเครื่องหมาย * สำหรับเครื่องหมาย & จะให้ค่า Address ของตัวแปรซึ่งอยูหลังเครื่องหมาย & ดังตัวอย่าง
ตัวอย่าง
#include "stdio.h"
main()
{
int *pt, a, b;
a = 30;
pt = &a;
b = *pt;
printf("%d\n",b);
}
จะได้ผลลัพท์ = 30
ความสัมพันธ์ของ Pointer และ Array
ใน C++ Pointer และ Array จะมีความสัมพันธ์กันมาก เมื่อใข้ Array โดยไม่ระบุ Index เลย Array จะทำหน้าที่ เสมือนเป็น Pointer ซึ่งชี้ไปที่ ส่วนต้นของ Array (ตัวแปร Array ตัวแรก) ดังเช่นใน Function gets() ซึ่งเราจะเขียนเฉพาะชื่อ Array เท่านั้น Function gets() จะนำตัวอักษรที่ป้อนทางแป้นพิมพ์ ไปเก็นใน Array ซึ่งถูกชี้โดย Pointer การผ่านค่าไป Function ใน C++ จะผ่านในรูปของ Pointer เท่านั้น
String
หมายถึง ชุด(array)ของตัวอักขระ(character) ที่เรียงต่อกัน ตริงจะเป็นคําหรือข้อความที่มีความหมาย ใน C++ ไม่มีชนิดข้อมูลประเภท string การกําหนด string คือการกําหนดเป็นอาร์เรย์ของข้อมูลชนิด char หลาย ๆ ตัวนํามาเชื่อมต่อกันเป็น string เช่น character 'C','o','m','p','u','t','e','r' เก็บไว้ในอาร์เรย์รวมเป็นข้อมูล string ซึ่งจะได้ข้อความ "Computer" ข้อมูล string เป็นได้ทั้งค่าคงที่(constant) และตัวแปร(variable)
การกําหนดค่าคงที่ให้ string
วิธีการกําหนดตัวแปรประเภทchar ให้เป็นอาร์เรย์เพื่อให้เก็บค่าคงที่
1. ประกาศตัวแปรอาร์เรย์ประเภท char ไม่ระบุขนาดของอาร์เรย์และกําหนดค่ามีรูปแบบดังนี้
char string_name[] = "string or text";
โดยที่ char คือ ประเภทข้อมูลของสตริงเป็น character
string_name[] คือ ชื่อของตัวแปรสตริง โดยที่[ ] กําหนดให้เป็นอาร์เรย์ของสตริงไม่ระบุขนาดของอาร์เรย์ C++ Compilerจะตรวจสอบและกําหนดขนาดจากค่าคงที่ด้านขวาของเครื่องหมายเท่ากับ "string or text" คือข้อความหรือสายอักขระที่เป็นค่าคงที่ของสตริงต้องเขียนไว้ในเครื่องหมาย " " เสมอ (ถ้าเป็นค่าคงที่ประเภท char ค่าคงที่เขียนไว้ในเครื่องหมาย ' ') เช่น
char name[] ="Sirichai Namburi";
char str[] = "C++ is OOP language";
เนื่องจากสตริงเป็นอาร์เรย์ของ char จึงสามารถกําหนดค่าคงที่ได้อีกวิธีหนึ่ง คือ
char name[] = {'S','i','r','i','c','h','a', 'i',' ','N','a','m','b','u','r', 'i','\0'};
สําหรับ'\0' หมายถึงเครื่องหมาย null ซึ่งใช้เป็นรหัสจบสตริงในภาษาC++
2. ประกาศตัวแปรอาร์เรย์ประเภทchar โดยระบุขนาดของอาร์เรย์และกําหนดค่า มีรูปแบบดังนี้
char string_name[n] = " string or text";
โดยที่ n คือขนาดของอาร์เรย์ 1 มิติ เช่น
char name[31]; //ตัวแปรname สามารถเก็บอักขระได้30 ตัวตัวที่31ใช้เก็บ'\0'
char location[50]; //ตัวแปรlocation สามารถเก็บอักขระได้49 ตัวตัวที่50 ใช้เก็บ'\0'
Pointer
คือ ตัวแปรที่เก็บตำแหน่งของหน่วยความจำ (memory address) ซึ่งตำแหน่งของหน่วยความจำนี้จะเป็นที่อยู่ของสิ่งอื่น ๆ (โดยทั่วไปจะเป็นตัวแปรอื่น) ในหน่วยความจำ เช่น ถ้าตัวแปรตัวหนึ่งเก็บตำแหน่งของตัวแปรอีกตัว เราอาจกล่าวได้ว่าตัวแปรตัวแรกนั้นชี้ไปยัง (point to) ตัวแปรที่สอง จะเก็บ Address ของตัวแปร แทนที่จะเก็บข้อมูลต่างๆ เหมือนตัวแปรชนิดอื่นๆ จากคุณสมบุติของ ตัวแปรชนิด Pointer จึงมองดูเหมือนกับ ตัวชี้ หรือพอยน์เตอร์ ซึ่งชี้ไปที่ Address ของตัวแปร
การกำหนดตัวแปร Pointer
จะคล้ายกับการกำหนดตัวแปรชนิดต่างๆ เพียงแต่ต้องมีเครื่องหมาย * หน้าชื่อตัวแปร ดังนี้
int *pt;
ในที่นี้กำหนดให้ pt เป็นตัวแปร Pointer ซึ่งเก็บ Address ของตัวแปรชนิดตัวเลขจำนวนเต็ม ในเรื่อง Pointer มีเครื่องหมาย 2 ชนิด คือ * และ & เครื่องหมาย * จะให้ค่า ของข้อมูล ซึ่งเก็บอยู่ใน Address โดย Address นี้เก็บ อยู่ในตัวแปร Pointer ซึ่งอยู่หลังเครื่องหมาย * สำหรับเครื่องหมาย & จะให้ค่า Address ของตัวแปรซึ่งอยูหลังเครื่องหมาย & ดังตัวอย่าง
ตัวอย่าง
#include "stdio.h"
main()
{
int *pt, a, b;
a = 30;
pt = &a;
b = *pt;
printf("%d\n",b);
}
จะได้ผลลัพท์ = 30
ความสัมพันธ์ของ Pointer และ Array
ใน C++ Pointer และ Array จะมีความสัมพันธ์กันมาก เมื่อใข้ Array โดยไม่ระบุ Index เลย Array จะทำหน้าที่ เสมือนเป็น Pointer ซึ่งชี้ไปที่ ส่วนต้นของ Array (ตัวแปร Array ตัวแรก) ดังเช่นใน Function gets() ซึ่งเราจะเขียนเฉพาะชื่อ Array เท่านั้น Function gets() จะนำตัวอักษรที่ป้อนทางแป้นพิมพ์ ไปเก็นใน Array ซึ่งถูกชี้โดย Pointer การผ่านค่าไป Function ใน C++ จะผ่านในรูปของ Pointer เท่านั้น
String
หมายถึง ชุด(array)ของตัวอักขระ(character) ที่เรียงต่อกัน ตริงจะเป็นคําหรือข้อความที่มีความหมาย ใน C++ ไม่มีชนิดข้อมูลประเภท string การกําหนด string คือการกําหนดเป็นอาร์เรย์ของข้อมูลชนิด char หลาย ๆ ตัวนํามาเชื่อมต่อกันเป็น string เช่น character 'C','o','m','p','u','t','e','r' เก็บไว้ในอาร์เรย์รวมเป็นข้อมูล string ซึ่งจะได้ข้อความ "Computer" ข้อมูล string เป็นได้ทั้งค่าคงที่(constant) และตัวแปร(variable)
การกําหนดค่าคงที่ให้ string
วิธีการกําหนดตัวแปรประเภทchar ให้เป็นอาร์เรย์เพื่อให้เก็บค่าคงที่
1. ประกาศตัวแปรอาร์เรย์ประเภท char ไม่ระบุขนาดของอาร์เรย์และกําหนดค่ามีรูปแบบดังนี้
char string_name[] = "string or text";
โดยที่ char คือ ประเภทข้อมูลของสตริงเป็น character
string_name[] คือ ชื่อของตัวแปรสตริง โดยที่[ ] กําหนดให้เป็นอาร์เรย์ของสตริงไม่ระบุขนาดของอาร์เรย์ C++ Compilerจะตรวจสอบและกําหนดขนาดจากค่าคงที่ด้านขวาของเครื่องหมายเท่ากับ "string or text" คือข้อความหรือสายอักขระที่เป็นค่าคงที่ของสตริงต้องเขียนไว้ในเครื่องหมาย " " เสมอ (ถ้าเป็นค่าคงที่ประเภท char ค่าคงที่เขียนไว้ในเครื่องหมาย ' ') เช่น
char name[] ="Sirichai Namburi";
char str[] = "C++ is OOP language";
เนื่องจากสตริงเป็นอาร์เรย์ของ char จึงสามารถกําหนดค่าคงที่ได้อีกวิธีหนึ่ง คือ
char name[] = {'S','i','r','i','c','h','a', 'i',' ','N','a','m','b','u','r', 'i','\0'};
สําหรับ'\0' หมายถึงเครื่องหมาย null ซึ่งใช้เป็นรหัสจบสตริงในภาษาC++
2. ประกาศตัวแปรอาร์เรย์ประเภทchar โดยระบุขนาดของอาร์เรย์และกําหนดค่า มีรูปแบบดังนี้
char string_name[n] = " string or text";
โดยที่ n คือขนาดของอาร์เรย์ 1 มิติ เช่น
char name[31]; //ตัวแปรname สามารถเก็บอักขระได้30 ตัวตัวที่31ใช้เก็บ'\0'
char location[50]; //ตัวแปรlocation สามารถเก็บอักขระได้49 ตัวตัวที่50 ใช้เก็บ'\0'
29.6.52
DTS 29-06-52
สรุปเนื้อหาบทเรียน "Array and Record"
อาร์เรย์__Array__^^"
....แถวหรือลำดับของข้อมูลชนิดเดียวกันที่มีจำนวนหลายตัวนำมาเก็บในตัวแปรชื่อเดียวกัน แต่ต่างกันที่ตัวบอกลำดับ ซึ่งเรียกว่าตัวห้อยหรือตัว Subscript ของตัวแปรนั้น
ประเภทของอาร์เรย์
....ตามชนิดของข้อมูล ได้ 2 ประเภท คือ อาร์เรย์ของตัวแปรที่เก็บข้อมูลจำนวนและอาร์เรย์ของตัวแปร Pointer
ถ้าแบ่งอาร์เรย์ตามลักษณะที่ตั้งของข้อมูล คือ ข้อมูลอยู่ในตำแหน่งที่เท่าใดของกลุ่มสมาชิกนั้น ๆ นั่นคือข้อมูลตัวนั้นอยู่ในแถวใด คอลัมน์ที่เท่าใด หรือถ้ามีหลายระนาบ (Plate) ก็คืออยู่ในระนาบใด เป็นต้น
ลักษณะดังกล่าวนี้เราเรียกว่า มิติ (Dimension) ซึ่งจะแบ่งได้เป็น 2 ประเภท คือ อาร์เรย์มิติเดียว (One Dimension) อาร์เรย์หลายมิติ (Multi Dimensions) คือตั้งแต่ 2 มิติขึ้นไป ความหมายของมิติเปรียบได้กับมิติของวัตถุชิ้นงานหรือแผ่นระนาบ (Plate) ดังนี้
อาร์เรย์มิติเดียว (one dimension)
อาร์เรย์มิติเดียว คือ ตัวแปรอาร์เรย์ที่ใช้เก็บข้อมูลเป็นกลุ่ม ที่มีลักษณะตำแหน่งที่ตั้งที่เป็นลักษณะแถวเดียว (วางตามนอน) หรือคอลัมน์เดียว (วางตามตั้ง) เช่น x[7], number[100], time[3] เป็นต้น
อาร์เรย์หลายมิติ ( Multi Dimension Array )
อาร์เรย์หลายมิติ คือ อาร์เรย์ตั้งแต่ 2 มิติเป็นต้นไป หมายถึงตัวแปรอาร์เรย์ที่ใช้เก็บข้อมูลเป็นกลุ่ม ที่ข้อมูลนั้นใช้ตัวแปรชื่อเดียวกันแต่มีข้อแตกต่างกันที่ตัวห้อย หรือ subscript ที่บอกลำดับความแตกต่างของตัวแปรนั้นว่าอยู่ในแถวใด ในคอลัมน์ที่เท่าไร ลำดับใดในแถว ที่กล่าวมานี้ คือ อาร์เรย์ 2 มิติ และถ้ากลุ่มข้อมูลดังกล่าวยังมีหลายชุดในที่นี้จะใช้คำว่า มีหลายระนาบ (Plate) ก็จะมีตัวห้อยเพิ่มมาอีกเพื่อระบุว่าเป็นของระนาบใด ลักษณะดังกล่าวนี้เป็นอาร์เรย์ 3 มิติ อาร์เรย์หลายมิติ คืออาร์เรย์ที่ถูกกำหนดขึ้นโดยใช้ [ ] หลายคู่ และเวลาติดต่อกับข้อมูลใด ในอาร์เรย์ ก็สามารถทำได้โดยใช้ตัวห้อย (Subscript) หลายตัว
__Structure__^^"
คือ การกำหนดขั้นตอนให้เครื่องคอมพิวเตอร์ทำงานโดยมีโครงสร้างการควบคุมพื้นฐาน 3 หลักการ ได้แก่
การทำงานแบบตามลำดับ(Sequence)
คือ การเขียนให้ทำงานจากบนลงล่าง เขียนคำสั่งเป็นบรรทัด และทำทีละบรรทัดจากบรรทัดบนสุดลงไปจนถึงบรรทัดล่างสุด สมมติให้มีการทำงาน 3 กระบวนการคือ อ่านข้อมูล คำนวณ และพิมพ์ จะเขียนเป็นผังงาน(Flowchart) ในแบบตามลำดับ
การเลือกกระทำตามเงื่อนไข(Decision)
คือ การเขียนโปรแกรมเพื่อนำค่าไปเลือกกระทำ โดยปกติจะมีเหตุการณ์ให้ทำ 2 กระบวนการ คือเงื่อนไขเป็นจริงจะกระทำกระบวนการหนึ่ง และเป็นเท็จจะกระทำอีกกระบวนการหนึ่ง แต่ถ้าซับซ้อนมากขึ้น จะต้องใช้เงื่อนไขหลายชั้น
การทำซ้ำ(Repeation or Loop)
คือ การทำกระบวนการหนึ่งหลายครั้ง โดยมีเงื่อนไขในการควบคุม หมายถึงการทำซ้ำเป็นหลักการที่ทำความเข้าใจได้ยากกว่า 2 รูปแบบแรก เพราะการเขียนโปรแกรมแต่ละภาษา จะไม่แสดงภาพอย่างชัดเจนเหมือนการเขียนผังงาน(Flowchart) ผู้เขียนโปรแกรมต้องจินตนาการ ถึงรูปแบบการทำงาน และใช้คำสั่งควบคุมด้วยตนเองเป็นการแสดงคำสั่งทำซ้ำ(do while) ซึ่งหมายถึงการทำซ้ำในขณะที่เป็นจริง และเลิกการทำซ้ำเมื่อเงื่อนไขเป็นเท็จ
อาร์เรย์__Array__^^"
....แถวหรือลำดับของข้อมูลชนิดเดียวกันที่มีจำนวนหลายตัวนำมาเก็บในตัวแปรชื่อเดียวกัน แต่ต่างกันที่ตัวบอกลำดับ ซึ่งเรียกว่าตัวห้อยหรือตัว Subscript ของตัวแปรนั้น
ประเภทของอาร์เรย์
....ตามชนิดของข้อมูล ได้ 2 ประเภท คือ อาร์เรย์ของตัวแปรที่เก็บข้อมูลจำนวนและอาร์เรย์ของตัวแปร Pointer
ถ้าแบ่งอาร์เรย์ตามลักษณะที่ตั้งของข้อมูล คือ ข้อมูลอยู่ในตำแหน่งที่เท่าใดของกลุ่มสมาชิกนั้น ๆ นั่นคือข้อมูลตัวนั้นอยู่ในแถวใด คอลัมน์ที่เท่าใด หรือถ้ามีหลายระนาบ (Plate) ก็คืออยู่ในระนาบใด เป็นต้น
ลักษณะดังกล่าวนี้เราเรียกว่า มิติ (Dimension) ซึ่งจะแบ่งได้เป็น 2 ประเภท คือ อาร์เรย์มิติเดียว (One Dimension) อาร์เรย์หลายมิติ (Multi Dimensions) คือตั้งแต่ 2 มิติขึ้นไป ความหมายของมิติเปรียบได้กับมิติของวัตถุชิ้นงานหรือแผ่นระนาบ (Plate) ดังนี้
อาร์เรย์มิติเดียว (one dimension)
อาร์เรย์มิติเดียว คือ ตัวแปรอาร์เรย์ที่ใช้เก็บข้อมูลเป็นกลุ่ม ที่มีลักษณะตำแหน่งที่ตั้งที่เป็นลักษณะแถวเดียว (วางตามนอน) หรือคอลัมน์เดียว (วางตามตั้ง) เช่น x[7], number[100], time[3] เป็นต้น
อาร์เรย์หลายมิติ ( Multi Dimension Array )
อาร์เรย์หลายมิติ คือ อาร์เรย์ตั้งแต่ 2 มิติเป็นต้นไป หมายถึงตัวแปรอาร์เรย์ที่ใช้เก็บข้อมูลเป็นกลุ่ม ที่ข้อมูลนั้นใช้ตัวแปรชื่อเดียวกันแต่มีข้อแตกต่างกันที่ตัวห้อย หรือ subscript ที่บอกลำดับความแตกต่างของตัวแปรนั้นว่าอยู่ในแถวใด ในคอลัมน์ที่เท่าไร ลำดับใดในแถว ที่กล่าวมานี้ คือ อาร์เรย์ 2 มิติ และถ้ากลุ่มข้อมูลดังกล่าวยังมีหลายชุดในที่นี้จะใช้คำว่า มีหลายระนาบ (Plate) ก็จะมีตัวห้อยเพิ่มมาอีกเพื่อระบุว่าเป็นของระนาบใด ลักษณะดังกล่าวนี้เป็นอาร์เรย์ 3 มิติ อาร์เรย์หลายมิติ คืออาร์เรย์ที่ถูกกำหนดขึ้นโดยใช้ [ ] หลายคู่ และเวลาติดต่อกับข้อมูลใด ในอาร์เรย์ ก็สามารถทำได้โดยใช้ตัวห้อย (Subscript) หลายตัว
__Structure__^^"
คือ การกำหนดขั้นตอนให้เครื่องคอมพิวเตอร์ทำงานโดยมีโครงสร้างการควบคุมพื้นฐาน 3 หลักการ ได้แก่
การทำงานแบบตามลำดับ(Sequence)
คือ การเขียนให้ทำงานจากบนลงล่าง เขียนคำสั่งเป็นบรรทัด และทำทีละบรรทัดจากบรรทัดบนสุดลงไปจนถึงบรรทัดล่างสุด สมมติให้มีการทำงาน 3 กระบวนการคือ อ่านข้อมูล คำนวณ และพิมพ์ จะเขียนเป็นผังงาน(Flowchart) ในแบบตามลำดับ
การเลือกกระทำตามเงื่อนไข(Decision)
คือ การเขียนโปรแกรมเพื่อนำค่าไปเลือกกระทำ โดยปกติจะมีเหตุการณ์ให้ทำ 2 กระบวนการ คือเงื่อนไขเป็นจริงจะกระทำกระบวนการหนึ่ง และเป็นเท็จจะกระทำอีกกระบวนการหนึ่ง แต่ถ้าซับซ้อนมากขึ้น จะต้องใช้เงื่อนไขหลายชั้น
การทำซ้ำ(Repeation or Loop)
คือ การทำกระบวนการหนึ่งหลายครั้ง โดยมีเงื่อนไขในการควบคุม หมายถึงการทำซ้ำเป็นหลักการที่ทำความเข้าใจได้ยากกว่า 2 รูปแบบแรก เพราะการเขียนโปรแกรมแต่ละภาษา จะไม่แสดงภาพอย่างชัดเจนเหมือนการเขียนผังงาน(Flowchart) ผู้เขียนโปรแกรมต้องจินตนาการ ถึงรูปแบบการทำงาน และใช้คำสั่งควบคุมด้วยตนเองเป็นการแสดงคำสั่งทำซ้ำ(do while) ซึ่งหมายถึงการทำซ้ำในขณะที่เป็นจริง และเลิกการทำซ้ำเมื่อเงื่อนไขเป็นเท็จ
การบ้าน__Structure__
#include
#include
main()
{
struct apartment{
int date;
int number_room;
char phone_number[20];
char name[20];
char last_name[20];
float price;
float price_water;
float price_light;
}apartment1;
printf ("date=");
scanf ("%d",&apartment1.date);
printf ("number_room=");
scanf ("%d",&apartment1.number_room);
printf ("phone_number=");
scanf ("%s",&apartment1.phone_number);
printf ("name=");
scanf ("%s",&apartment1.name);
printf ("last_name=");
scanf ("%s",&apartment1.last_name);
printf ("price=");
scanf ("%f",&apartment1.price);
printf ("price_water=");
scanf ("%f",&apartment1.price_water);
printf ("price_light=");
scanf ("%f",&apartment1.price_light);
printf ("Date=%d\n",apartment1.date);
printf ("number_room=%d\n",apartment1.number_room);
printf ("phone_number=%s\n",apartment1.phone_number);
printf ("name=%s\n",apartment1.name);
printf ("last_name=%s\n",apartment1.last_name);
printf ("price=%f\n",apartment1.price);
printf ("price_water=%f\n",apartment1.price_water);
printf ("price_light=%f\n",apartment1.price_light);
}
ประวัติ

นางสาว หนึ่งฤทัย จำนงค์
Miss Nungruthai Jamnong
รหัสนักศึกษา 50152792003
หลักสูตร : การบริหารธุรกิจ (คอมพิวเตอร์ธุรกิจ)
คณะวิทยาการจัดการมหาวิทยาลัยราชภัฏสวนดุสิต
e-mail : u50152792003@gmail.com
สมัครสมาชิก:
บทความ (Atom)
